歡迎來到第 18 天,首先祝各位中秋愉快!那今天就伴隨著各種炭火味開始今天主題吧!
繼昨天成功透過 Selenium 模擬登入,今天我們要進入下一個階段也就是透過 IG 的 Hashtag 方式進行圖片搜索以及下載。
首先我們透過人為的方式進行 Hashtag 的搜尋,並觀察 Network 資料傳遞狀況。在我們送出 #marutaro 的搜尋時,會看到 Network 出現一個對 https://www.instagram.com/explore/tags/marutaro/?__a=1 的請求,而觀察 Response 的內容,是一個 JSON 格式的資料並包含了許多圖片的 URL 位置及時間相關資訊。
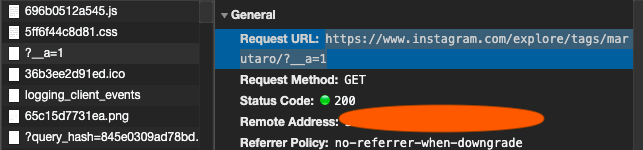

在觀察的過程意外發現 https://www.instagram.com/explore/tags/marutaro/?__a=1 的請求並沒有登入需求,亦即可透過 requests 的方式直接取得我們所需的資料。
首先先處理請求所得到的 JSON 資料,我們可以透過 response.json() 的方式將 JSON 轉成 python 熟悉的 dict 資料格式,在進行分析
import requests
response = requests.get("https://www.instagram.com/explore/tags/marutaro/?__a=1")
data = response.json()
在分析完整個 json 檔後會發現所有的圖片都藏在 graphql/hashtag/edge_hashtag_to_top_posts/edges 這個結構之下,因此只要一個 for 迴圈就可以調出所有的圖片網址
urls = []
for post in data['graphql']['hashtag']['edge_hashtag_to_top_posts']['edges']:
urls.append(post['node']['display_url'])
接下來就是下載了,但怎麼透過 python 實踐下載呢?下載的拆解其實就是傳送請求到圖片位置,得到圖片 bytes 的資料回傳,在預計儲存的位置新開啟一個檔案,並將為傳值寫入並關閉,這樣就完成下載流程了
for i, url in enumerate(urls):
with open(f'{預計儲存路徑}/maru_{i}.png','wb') as f:
f.write(requests.get(url).content)
這樣就下載完所有柴犬 Maru 的所有照片了!但打開資料夾才發現,怎麼只有 9 張?這會牽扯到明天要談論的主題無限捲軸的問題,那今天就先到這裡,明天見!

